
The problem this solves
Before any Oracle 26ai experiment can produce meaningful results (assessing the feasibility of a use case, benchmarking ONNX embedding models, validating retrieval quality, measuring precision and recall, or delivering a PoC fast enough to share with project leadership), you need real, structured data in your Oracle tables. Not five handcrafted rows that confirm the SQL syntax works. Data with enough variety, semantic richness, and realistic distribution to tell you whether your vector search approach actually holds under real conditions.
Two paths exist and both stall before the experiment starts. Building test data manually produces inconsistent rows and takes hours; the result is rarely rich enough to distinguish between model choices or validate retrieval behaviour across categories. Production data, on the other hand, is blocked by confidentiality and structural-readiness constraints that are standard in any enterprise environment before a PoC is approved. Oracle 26ai’s own documentation examples are intentionally toy-scale: five rows confirm syntax, not retrieval quality.
This series started as an attempt to build and share reproducible Oracle 26ai experiments on a public blog. The chosen use case was an insurance claims application that required car damage photographs: varied enough across damage types to produce meaningful similarity groupings, each accompanied by a natural-language description, and free from copyright restrictions. Assembling that by hand turned out to be the first real blocker, before a single Oracle SQL query was written. That is what led to HuggingFace.
HuggingFace open datasets are the practical answer to this bottleneck. This series uses tahaman/DamageCarDataset as the running dataset throughout: 150 real car damage photographs across four damage classes, each paired with a natural-language description. An insurance claims application (matching past claims by visual and text similarity) is the practical use case we build toward. But the workflow this article establishes (select a dataset, import it into Oracle, wire up the VECTOR column) applies to any domain where a team needs to move from idea to working experiment without waiting for data engineering.
After following this guide, you will have a 150-row Oracle 26ai table with real car damage images and text descriptions, enough data to benchmark ONNX models, validate retrieval quality, and run a convincing PoC, loaded in a single session.
Who this is for
This guide is for Oracle practitioners (developers, architects, DBAs) who want to experiment with Oracle AI database features, specifically Vector Search, without spending the first session building test data by hand. The problem being solved here is setup time, not SQL syntax.
This is Part 1 of the CLIP experiment arc: data preparation. Loading ONNX models, generating embeddings, and running similarity queries come in later posts. Before any of that is useful, the Oracle table needs real, structured content with enough semantic variety to produce meaningful results.
It is not for teams building production ingestion pipelines or governed data workflows. This is an experiment accelerator pattern, scoped deliberately to local, repeatable Oracle AI experiments where the goal is learning, not production throughput.
The approach
The pattern separates two concerns that are usually conflated: data sourcing and Oracle AI work. HuggingFace handles the first entirely. Oracle 26ai handles the second entirely.
On the data side: the datasets Python library pulls tahaman/DamageCarDataset in one call, giving 150 rows of structured Parquet data with embedded images and text descriptions. The script inspects ds.features at runtime to infer Oracle column types and generate the CREATE TABLE DDL automatically; no table definition is ever written by hand. It then loads all rows into Oracle using executemany. The table schema holds everything the CLIP series needs: a BLOB column for images, a VARCHAR2 column for text descriptions sized by sampling actual values, and a VECTOR column left NULL at this stage, ready for embedding generation in the next post.
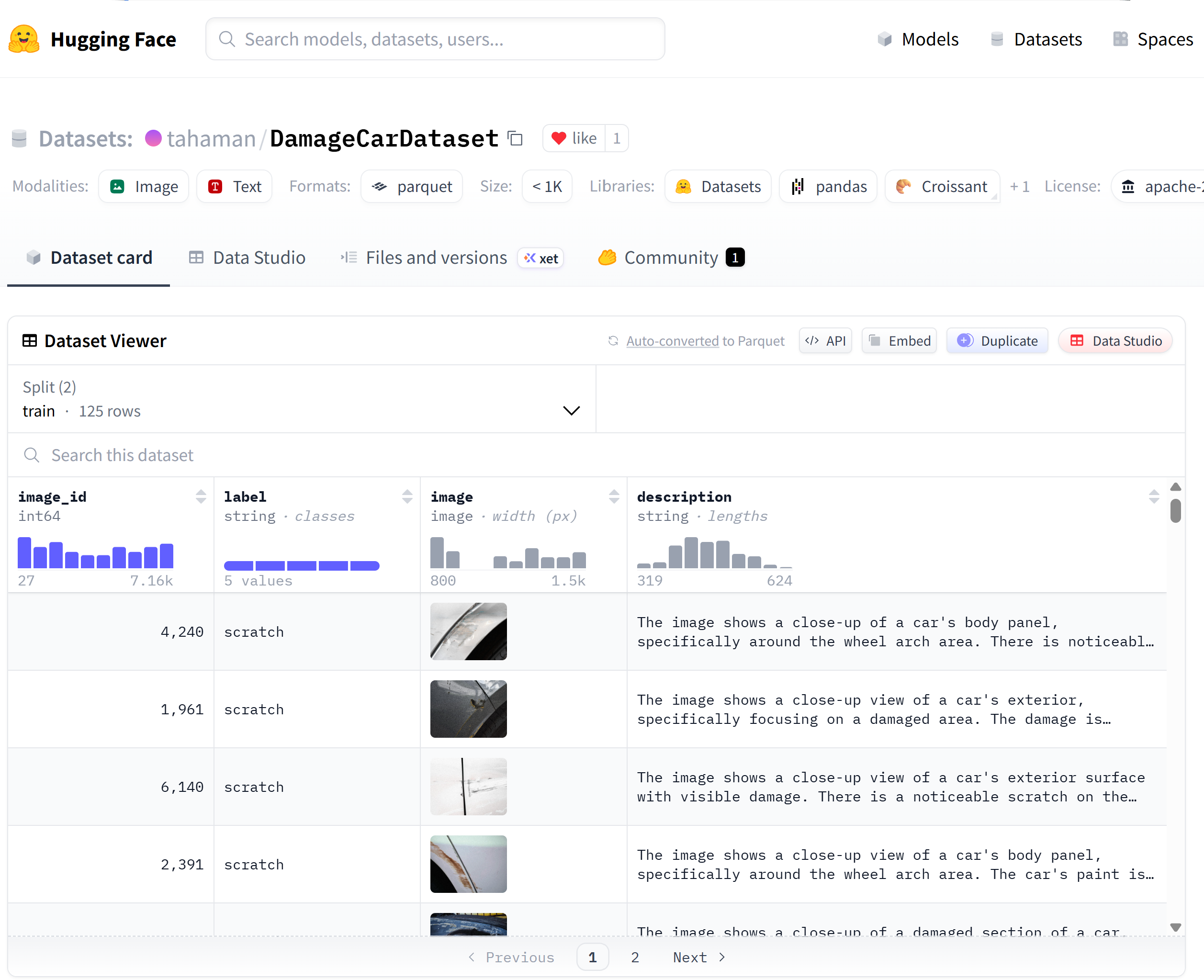 Hugging Face dataset tahaman/DamageCarDataset
Hugging Face dataset tahaman/DamageCarDataset
On the Oracle side, nothing happens in this post except receiving the data. No Python pipeline runs during inference. When Oracle’s CLIP ONNX model is loaded in the next post, VECTOR_EMBEDDING() will process the BLOB column directly inside the database, no external process needed. The key design constraint is this separation: data sourcing happens once, then Oracle owns everything.
Architecture
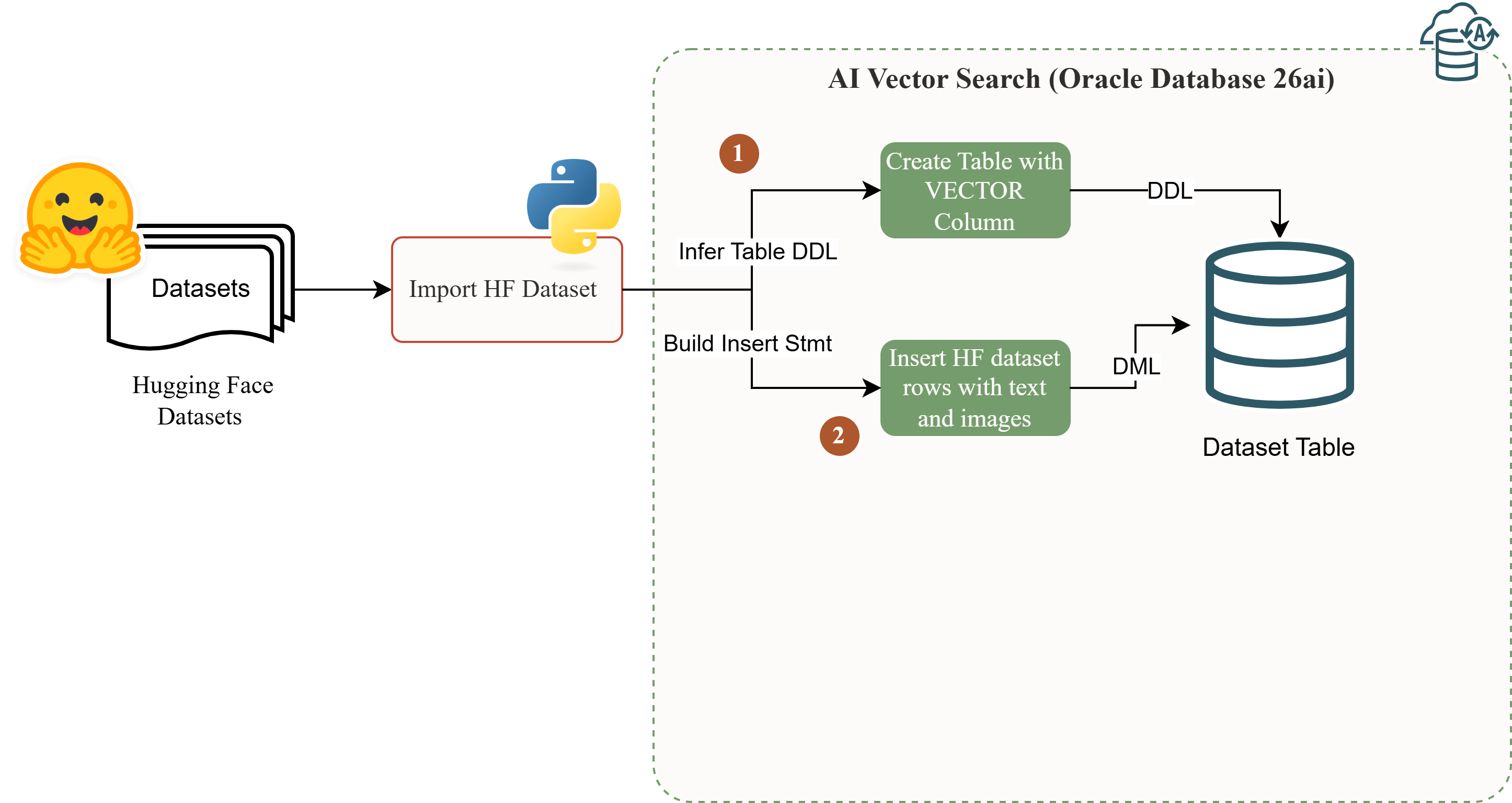 Data sourcing and Oracle AI work are independent operations. HuggingFace populates the table once; all embedding and retrieval work runs inside Oracle SQL.
Data sourcing and Oracle AI work are independent operations. HuggingFace populates the table once; all embedding and retrieval work runs inside Oracle SQL.
What lives inside Oracle after this post:
damage_car_tablewithBLOB,VARCHAR2, andVECTOR(*, FLOAT32)columns, schema inferred fromds.features- 150 rows of real car damage data
- Table annotations carrying HuggingFace dataset card metadata (
hf_modalities,hf_formats,hf_size_category,hf_libraries,hf_license)
What stays outside Oracle:
- One-time HuggingFace dataset download via the Python
datasetslibrary - The Oracle CLIP
.onnxfile from the model catalog (staged and loaded in the next post)
The key architectural constraint: The VECTOR column is created now but populated later. Oracle populates it via VECTOR_EMBEDDING(), not Python. This keeps the embedding pipeline entirely inside the database.
Prerequisites
| Requirement | Details |
|---|---|
| Oracle version | Oracle Database 26ai Free, running in Docker |
| Lab setup | Local Docker lab from post #1 in this series |
| Oracle features | DBMS_VECTOR, VECTOR column type, VECTOR_EMBEDDING() |
| Python | 3.10+ with oracledb, datasets, pillow, huggingface_hub (pip install oracledb datasets pillow huggingface_hub) |
| Model file | Not needed for this post, used in the next post |
| Estimated time | 15–20 minutes |
Assumed knowledge: Docker basics and connecting to an Oracle PDB with sqlplus or SQL Developer.
Step-by-step
Full code: github.com/assoudi-typica-ai/pre-built-multi-modal-clip-embedding-series This section covers the key steps and decisions. Not every line.
Step 1, Create the database user and wire up the ONNX directory
clip_demo_setup.sql runs as SYS and does three things: creates the demo_vec user, grants CREATE MINING MODEL (required for DBMS_VECTOR.LOAD_ONNX_MODEL in the next post), and creates the ONNX_TMP Oracle DIRECTORY object pointing to /tmp inside the container. Creating it now avoids a setup dependency later.
| |
What can go wrong here: DIRECTORY objects must be created as SYS. If the setup script runs as demo_vec, the directory creation fails silently, and LOAD_ONNX_MODEL in a later post will report a file-not-found error that points to the wrong root cause.
Step 2, Create the table and import the HuggingFace dataset
This step creates the Oracle table and populates it with the DamageCarDataset, the foundation for every post in this series.
Why this dataset, and why it supports the full experiment arc:
The CLIP experiment series runs as follows: this post loads 150 car damage cases (images + descriptions) into Oracle. The next post generates 512-dim CLIP image embeddings with CLIP_VIT_BASE_PATCH32_IMG. The post after that runs text similarity using CLIP_VIT_BASE_PATCH32_TXT on the same descriptions. The final post crosses both modalities for the insurance claims PoC. tahaman/DamageCarDataset supports this entire arc because of three specific properties:
- Dual modality: Every row has a
BLOB-compatible image and aVARCHAR2-compatible text description. The same table supports image search, text search, and cross-modal retrieval without restructuring. - Semantic variety: Four distinct damage classes (scratch, dent, tire flat, glass shatter) provide enough visual and textual variation to test whether similarity groupings are meaningful across categories.
- Structural clarity: Train/test splits are already present, useful when later posts build evaluation pipelines and need held-out data.
clip_demo_import_dataset.py creates the table and inserts all rows in one run. The table DDL is inferred from ds.features; no SQL file is needed at this stage. Use --dry-run to preview the inferred schema before touching the database:
| |
| |
The type mapping is handled by _feature_to_oracle, which returns both an Oracle type string and a transform function for each HuggingFace feature:
| |
For Value('string') columns, the default VARCHAR2(4000) is further refined by _analyze_string_cols, which scans actual row values before generating DDL and picks VARCHAR2(255), VARCHAR2(4000), or CLOB based on what the data contains. label comes out as VARCHAR2(255); description comes out as VARCHAR2(4000). This matters because VARCHAR2 columns can be indexed; CLOB columns cannot.
When the schema looks correct, run without the flag:
| |
The script drops any existing table, creates the new one with the inferred DDL, annotates it with Hub metadata, and inserts all 150 rows in a single executemany call:
DROP TABLE IF EXISTS ... PURGE (Oracle 23ai syntax) makes reruns idempotent. PURGE bypasses the recycle bin, appropriate for experiment tables that are always rebuilt from source.
Verification
After Step 2, confirm the data loaded correctly:
Expected output:
The embedding column is NULL at this stage. Part 2 of this series loads CLIP_VIT_BASE_PATCH32_IMG via DBMS_VECTOR.LOAD_ONNX_MODEL and populates it with a single SQL UPDATE. After that runs, VECTORIZED reads 150.
Confirm the table was annotated with dataset card metadata:
Expected: rows for hf_dataset, hf_formats, hf_libraries, hf_modalities, hf_num_rows, hf_size_category, hf_license.
Takeaways
Schema inference from ds.features removes the manual DDL step, and VARCHAR2 sizing makes it accurate, not just convenient. The script inspects the HuggingFace feature map at runtime and generates the CREATE TABLE DDL automatically.
Python-external import has concrete tradeoffs against Oracle-native alternatives. The oracledb thin-mode approach is the correct choice for image datasets because the images in DamageCarDataset are embedded as Arrow binary in Parquet. The rule: if the dataset requires any transformation before storage (image format conversion, encoding, enrichment), Python is the right tool. If the dataset maps cleanly to Oracle column types with no transformation, DBMS_CLOUD.COPY_DATA is the simpler path, fully Oracle-native with no external process.
Oracle 26ai table annotations turn the schema into its own data dictionary entry. After the import, the script runs ALTER TABLE ... ANNOTATIONS (ADD hf_dataset '...', ADD hf_modalities 'image, text', ADD hf_formats 'parquet', ...), pulling values from the HuggingFace Hub dataset card via the huggingface_hub library. This matters for repeatability: anyone inheriting the Oracle schema can see exactly where the data came from without reading the import script.
Final take
The first post in this series removed environment friction: Oracle 26ai running locally in Docker. This post removes data friction: a 150-row Oracle table with real car damage photographs and natural-language descriptions, ready to receive embeddings. Together, these two posts establish the foundation that makes the rest of the series possible: an environment that runs and data that is real.
What comes next is Oracle-side work exclusively. CLIP_VIT_BASE_PATCH32_IMG turns the image column into 512-dim vectors. CLIP_VIT_BASE_PATCH32_TXT maps the description column into the same vector space. A final post crosses both modalities for the insurance claims similarity search. The damage_car_table built here is the foundation for all of it.
HuggingFace datasets are not a production data strategy. They are an experiment accelerator: they return the setup time that would otherwise go to data curation back to the Oracle AI work where the actual learning happens.
The value of a public dataset is not the data. It is the experiment time it returns to the problem you are actually trying to solve.
Related assets
| Asset | Link |
|---|---|
| GitHub repo (full code) | assoudi-typica-ai/pre-built-multi-modal-clip-embedding-series |
| Series post #1 | Building a Local Oracle 26ai Free Lab with Docker on Windows |
Next in this series
damage_car_tablenow has 150 real car damage cases, images and text descriptions, with an emptyVECTORcolumn waiting for embeddings. Part 2 loads Oracle’sCLIP_VIT_BASE_PATCH32_IMGviaDBMS_VECTOR.LOAD_ONNX_MODELand generates 512-dim CLIP vectors for every image in a single SQL UPDATE. That is where the similarity search begins.